French Text Difficulty Prediction
Competition: Kaggle — 2nd Place
Period: Feb – Jun 2024
Fine-tuned FlauBERT for CEFR classification (A1–C2) achieving 78% accuracy. Model successfully deployed via a Streamlit web app.
View the full project code on GitHub.
1. Project Overview
1.1 Problem Description
When learning a new language like French, it is critical for learners to engage with texts and multimedia content that are appropriately challenging—neither too easy nor too difficult. People learning French often face difficulties in finding reading materials and video content that match their specific proficiency levels, which range from beginner (A1) to advanced (C2). Traditional methods of selecting texts and videos can be subjective and inconsistent, hindering steady progress in language acquisition. Moreover, learners may struggle to identify which materials suit their current comprehension abilities, leading to potential frustration and decreased motivation. To support learners effectively, there is a pressing need for a tool that can automatically evaluate and classify the difficulty of French texts and the spoken content in French-language videos on platforms like YouTube. This project aims to develop a predictive model that assesses the difficulty level of both written texts and video in French, thereby helping learners to select materials that align with their learning needs and enhance their overall educational experience.
1.2 Sustainability
The predicting French text difficulty model also aligns with the current sustainable development goals. Here’s how the app’s sustainability features correspond to specific Sustainable Development Goals (SDGs):
SDG 4: Quality Education
![]()
- Educational Sustainability: The app enhances lifelong and autonomous learning by providing tailored language materials according to learners’ proficiency levels, improving educational efficiency and reducing resource use.
SDG 9: Industry, Innovation, and Infrastructure
![]()
- Technological Sustainability: The app continually updates with the latest language processing technologies and machine learning advancements, ensuring accuracy, relevance, and the ability to include additional languages, thus extending its market longevity.
SDG 11: Sustainable Cities and Communities
![]()
- Environmental Sustainability: By decreasing reliance on physical educational resources and supporting remote learning, the app helps reduce paper usage, waste, and carbon emissions associated with traditional educational methods.
SDG 10: Reduced Inequalities
![]()
- Cultural and Social Sustainability: The app facilitates access to language learning for diverse user groups, including economically disadvantaged learners, promoting multicultural engagement and educational equity.
SDG 8: Decent Work and Economic Growth
![]()
- Economic Sustainability: The app creates a sustainable revenue stream through subscriptions and licenses, funding continuous improvement and attracting investment from the educational technology sector, contributing to economic growth and sustainable employment.
1.3 Overall Objective
To address the challenges outlined previously, this project is divided into two main components:
- The first part concentrates on solving the text classification issue by identifying and optimizing the best model to predict the difficulty of French texts.
- The second part is dedicated to enhancing the user interface to ensure that the application is user-friendly and effective for learners.
2. Data Preparation
Original Dataset
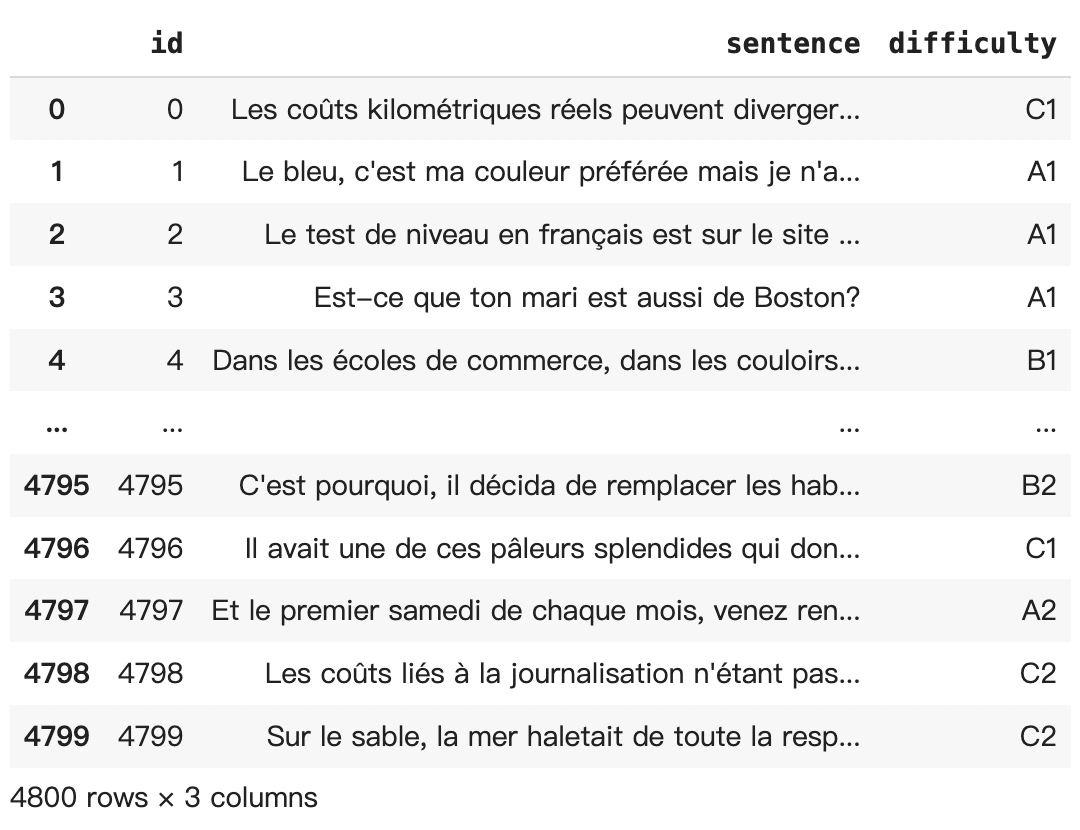
For LogoRank, effective data preparation is crucial for training our models to accurately predict the difficulty level of French texts. Below is an overview of our data preparation process:
Data Augmentation
To enhance the robustness of our models and increase the diversity of our training examples, we implemented a data augmentation strategy. Our approach involved the following steps:
- Sentence Swapping: Each sentence in the dataset was swapped within its document while preserving the original structure of the text. This method maintains the semantic integrity of the document and ensures that the augmented sentences retain the same difficulty level as the original.
- Appending Augmented Data: Each swapped sentence was then appended to the training dataset as a new data point. This effectively increased the size of our training dataset, allowing our models to learn from a broader array of sentence structures and contexts without introducing label noise.
Rationale
The decision not to clean the data was based on an initial assessment which suggested that the dataset was already in good form without major inconsistencies or errors. This approach allowed us to focus our efforts on model training and refinement.
Through this data preparation process, we aimed to create a training environment that mimics real-world applications, where the variety of text structures and contexts is vast. This method prepares our models to perform well across different styles and complexities of French texts.
Final Dataset
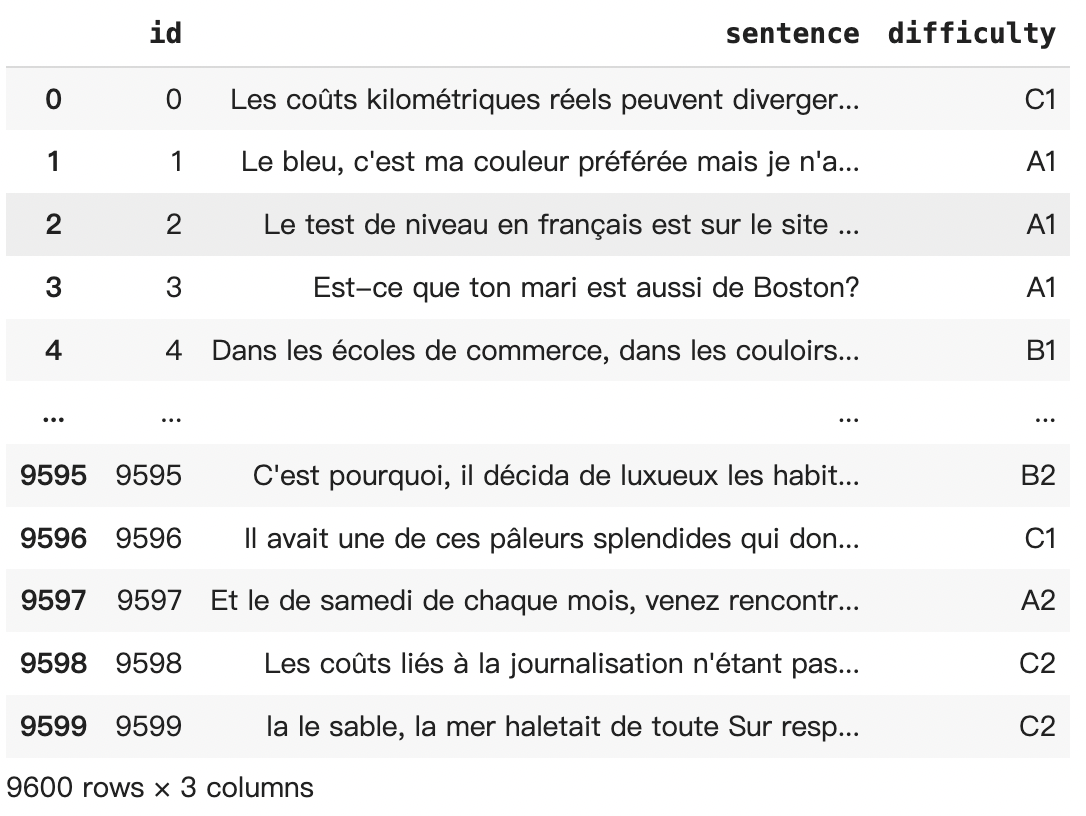
3. Find the best model to predict the difficulty of French texts
3.1 Objective
This part aims to identify the most effective approach for predicting the difficulty level of French texts. To achieve this, the following steps are implemented:
- Feature Extraction: The model processes French texts by converting them into a structured numerical format that encapsulates essential linguistic features.
- Classifier Selection: An advanced language model specifically designed for French is utilized to interpret and analyze the complexity of the texts.
- Difficulty Prediction: The trained model evaluates and classifies the difficulty level of French texts, optimizing learning paths for users at various proficiency levels.
3.2 Best Model Selection: FlauBERT
3.2.1 Overview
In the project, after evaluating multiple machine learning models, we selected FlauBERT as the most effective for classifying the difficulty levels of French texts. FlauBERT, which is designed specifically for the French language and pre-trained on a vast corpus of French texts, excelled in preliminary tests with our augmented dataset, demonstrating superior capability in handling the complexities of French grammar and vocabulary. We prepared a labeled dataset with French texts corresponding to CEFR difficulty levels from A1 to C2, employing an augmented dataset that enhances text structure variability while preserving difficulty integrity. Texts were tokenized using FlaubertTokenizer set to a maximum length of 128 tokens to balance contextual richness with computational efficiency. We initialized FlauBERTForSequenceClassification with six output labels to match the dataset’s six difficulty levels, ensuring precise alignment with the expected classifications. This setup positions the project to optimize model performance through multiple training phases, making it ideal for researchers and developers in need of high-performing text classification solutions.
3.2.2 Best model
- Full Dataset Utilization: We trained the model on the entire labeled dataset provided by the competition, without holding out a separate validation set. This approach was chosen to maximize the learning potential from the available data.
- Iterative Training Loops: To further enhance model performance, we implemented a two-loop training process:
- First Loop: The initial training phase involved adjusting general model parameters to adapt the pre-trained FlauBERT to our task-specific data. We used 5 training epochs, a batch size of 32, and a warmup step count of 500 to help stabilize the learning rate early in training.
- Second Loop: In the second training phase, we fine-tuned specific parameters that influence learning rates and optimization, allowing the model to adjust more delicately to the complexities of the task. At the end the same training parameters were used to continue training the model for another 5 epochs. This additional training helped to refine the model’s understanding of text complexities and further improve its prediction accuracy.
These adjustments were essential for tailoring the pre-trained FlauBERT model to our specific needs, leading to improved accuracy and robustness in predicting the difficulty levels of French texts.
3.2.3 Performance Evaluation
Compute metrics
We use train_test_split from sklearn.model_selection to divide the dataset into a training set and a validation set, with 10% serving as validation data for periodic performance assessment. It employs Trainer from the Hugging Face transformers library, configured with TrainingArguments to evaluate the model at the end of each epoch, using metrics including accuracy and F1 score computed through a compute_metrics function to measure its efficacy in classifying French texts by difficulty levels. After initial training and saving, the script allows for optional continued training to further optimize the model on the same or additional data, adjusting parameters or extending epochs to enhance accuracy and F1 scores.
First Training Run:
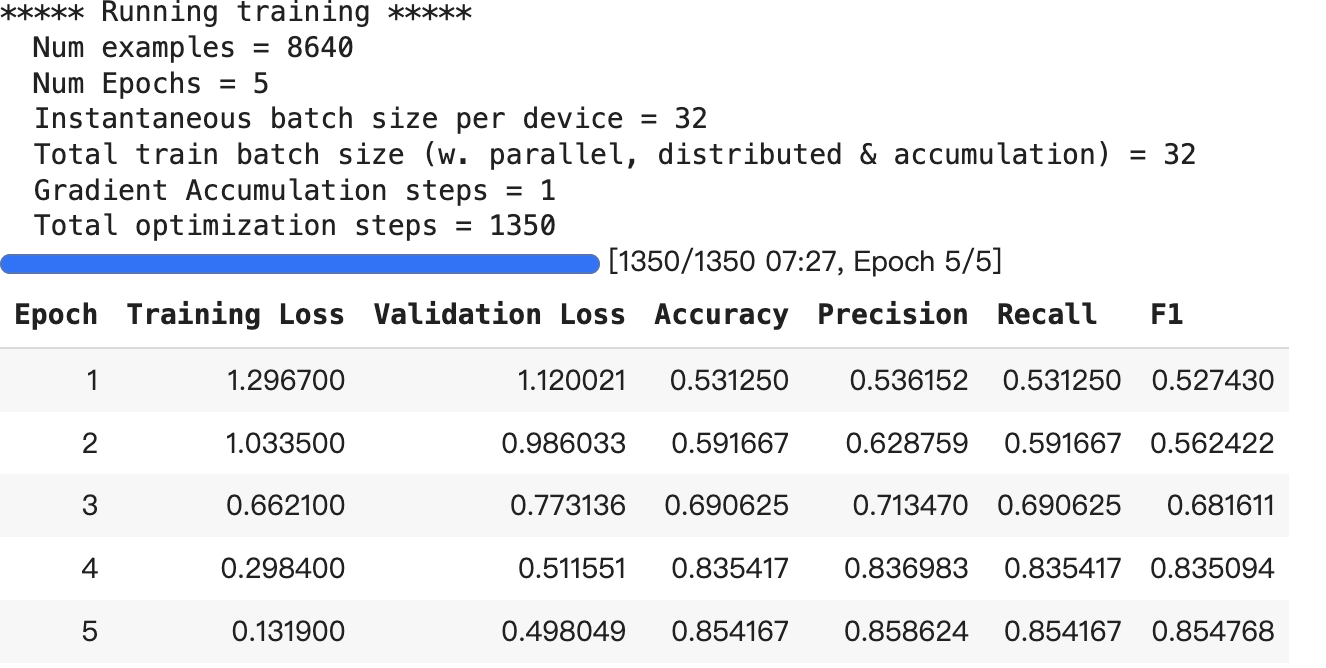
- Training Loss significantly reduced from 1.2967 to 0.1319, indicating that the model effectively optimized its parameters and reduced errors during the learning process.
- Validation Loss decreased from 1.1200 to 0.4980, demonstrating enhanced generalization capabilities of the model on unseen data.
- Accuracy, Precision, Recall, and F1 Score all improved markedly, especially the F1 score which increased from 0.5274 to 0.8548, showing the model’s improved performance in balancing the recognition of positives and avoiding false positives.
Second Training Run:
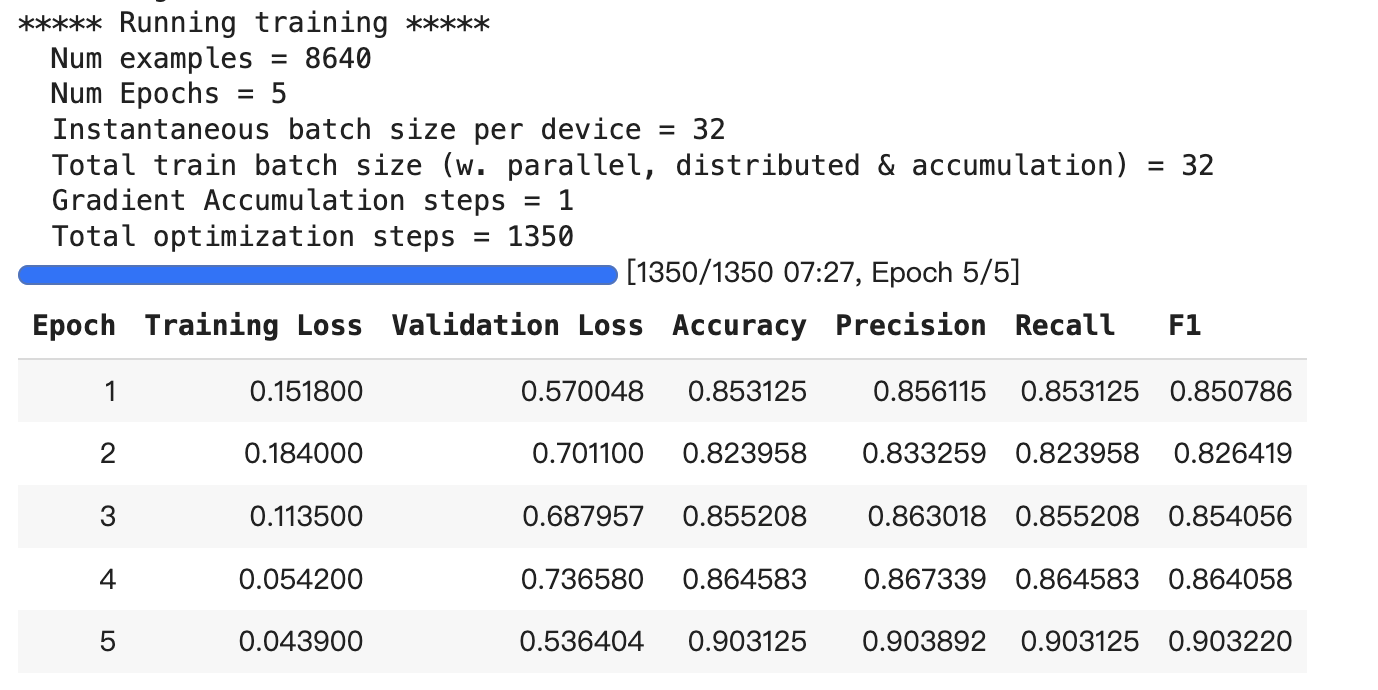
- Training Loss further decreased, starting at 0.1518 and ending at 0.0439, indicating a more efficient training process.
- Validation Loss remained relatively stable and finally decreased slightly to 0.5364.
- Performance Metrics reached higher levels after the second training, particularly with accuracy improving to 0.9031, reflecting enhanced understanding and classification ability of the dataset by the model.
Comprehensive Evaluation: These results illustrate consistent progress in the model as training progresses, particularly noticeable in the key performance indicators. Model performance in the second training generally surpassed the first, likely due to optimized training strategies, parameter adjustments, or more effective data handling techniques.
Confusion Matrix
Post-training, we extend its evaluation methods to include the generation of a confusion matrix. This confusion matrix displays the performance of the model in classifying French texts into different difficulty levels after additional training.
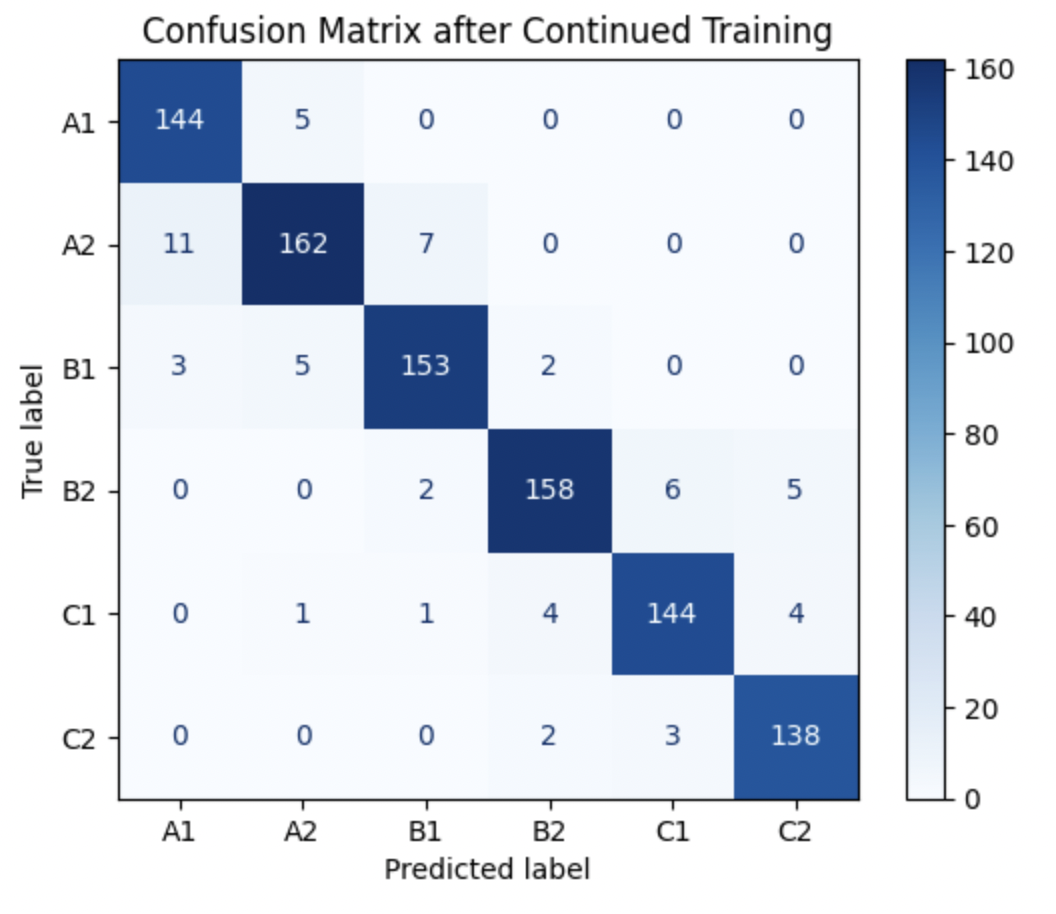
Key Insights: - A1 and A2: High accuracy with few misclassifications. A1 had 144 correct predictions and 5 misclassifications as A2. A2 had 162 correct predictions with minor confusion with A1 and B1. - B1 and B2: Good performance with some room for improvement. B1 had 153 correct predictions but was sometimes confused with A1, A2, and B2. B2 was mostly misclassified as adjacent categories C1 and C2. - C1 and C2: Correct predictions were 144 for C1 and 138 for C2, with some confusion noted between these two highest difficulty levels and B2.
Conclusion: The model performs well for lower difficulty levels (A1, A2) with minimal errors. For higher difficulty levels (B2, C1, and C2), the model faces challenges distinguishing between adjacent categories, likely due to similar features in texts of close difficulty levels.
3.2.4 Predict Test Data and Result
Test Dataset
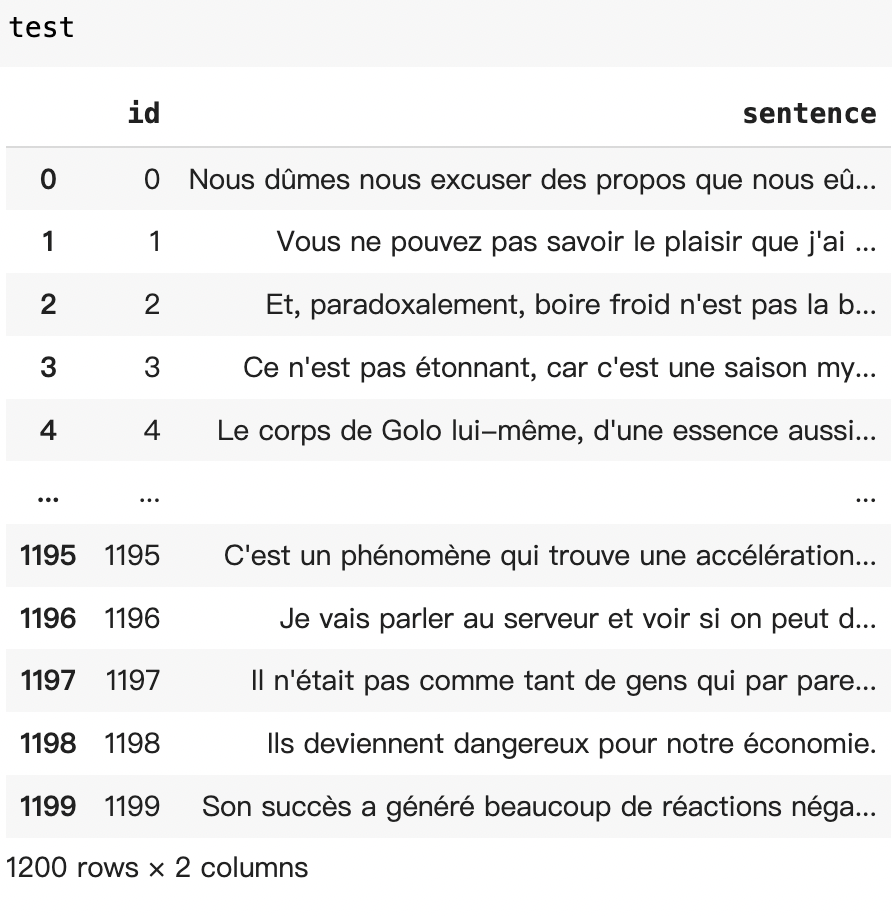
To validate our model’s real-world accuracy, we tested it with unlabelled test data and submitted the results to Kaggle, achieving an accuracy of 0.638. This outcome demonstrates the effectiveness of our two-phase training approach in fine-tuning a language-specific pre-trained model for specialized tasks like text difficulty classification.
3.2.5 Conclusion
The success of FlauBERT in our project underscores the importance of choosing a model well-suited to the language and nature of the task. Additionally, the iterative fine-tuning strategy highlights the benefits of a phased approach to training deep learning models, particularly when working with complex datasets.
3.3 Alternative Models - Feature Extraction and Difficulty Prediction with Camembert
3.3.1 Overview
This model utilizes the Camembert BERT model to extract features from French sentences and predict their difficulty levels using a classifier trained on different language complexity data. It is designed to assess the proficiency level required to comprehend each sentence, categorizing them from A1 (easiest) to C2 (most difficult) based on the Common European Framework of Reference for Languages (CEFR).
3.3.2 Feature Extraction
The bert_feature function is responsible for converting French sentences into a numerical format that represents linguistic features. This is achieved by: - Tokenizing the sentences using the CamembertTokenizer from the Hugging Face transformers library. - Feeding these tokens into the CamembertModel to obtain embeddings. - Calculating the average of these embeddings across all tokens produces a single feature vector per sentence. This averaging method incorporates the contributions of each word, ensuring a balanced representation that reflects the entirety of the sentence. This approach is particularly valuable in tasks like difficulty prediction, where the context and complexity of each word collectively determine the overall difficulty level of the sentence.
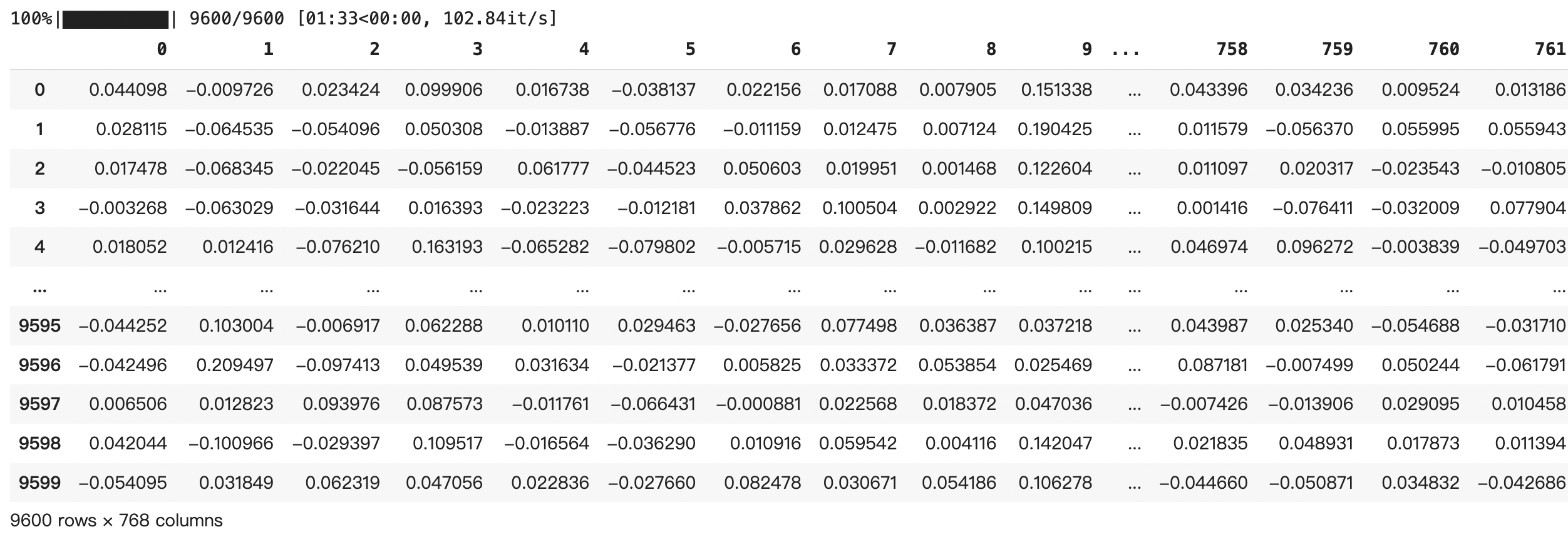
3.3.3 Select Classification
After extracting features, we use these features to test various pre-trained classifiers, including SVC, Logistic Regression, Random Forest, Extra Trees, Decision Tree, LightGBM, CatBoost, and MLP. We assess their performance on a test set, which is derived from the original dataset.
We have split the dataset into a training set and a test set in a 9:1 ratio. The target variables have been numerically encoded using LabelEncoder to represent the six difficulty levels: A1, A2, B1, B2, C1, and C2 as numbers 0 through 5.
Additionally, we implemented an evaluation function to measure each model’s effectiveness on the test set. This function calculates accuracy, precision, recall, and F1 scores to assess the models’ overall accuracy, precision in identifying correct classifications, completeness of the positive predictions, and the balance between precision and recall. The comparison results are as follows:

3.3.4 Discussion and Conclusion
Despite our MLP model achieving high accuracy on our test set (approximately 0.8), its performance dropped significantly to 0.553 when predicting unlabeled test data in a Kaggle competition. Notably, other models also showed similar accuracy around 0.5 on Kaggle.
We find that the model demonstrates strong performance on the test data but significantly underperforms on the diverse and unseen data from Kaggle, suggesting overfitting to the training data’s specific characteristics and noise. This means it’s really good at handling the specific types of data it trained on but struggles with new, different data from Kaggle. The likely cause of this issue is that our training data might not represent the wider variety of data on Kaggle, particularly in terms of how the labels are distributed.
Therefore, due to these issues, we ultimately decided to abandon the Camembert model approach. This decision was driven by the model’s poor adaptability to new and diverse datasets.
3.4 Comparison of Model Approaches
Upon evaluating different models for predicting the difficulty of French texts, we observed significant differences in their performances. Initially, we considered using the Camembert-based method for its advanced linguistic understanding capabilities. However, our comparative analysis showed that while Camembert excelled in controlled test environments, it was prone to overfitting and had scalability issues when applied to broader, more diverse datasets such as those found in the Kaggle competition.
In contrast, the Flaubert model demonstrated a higher accuracy of 0.640 on the Kaggle platform. Unlike Camembert, Flaubert proved to be better suited for this specific task due to its robustness across different data distributions and its more stable performance in varied testing conditions. This model provided a more balanced approach, efficiently handling the nuances of text difficulty classification without the computational intensity and overfitting concerns associated with Camembert.
3.5 Results and Discussion
The decision to switch to the Flaubert model was further validated by its outstanding performance on the Kaggle dataset, where it achieved an accuracy of 0.640. This not only demonstrated the model’s practical effectiveness in real-world applications but also led us to achieve a remarkable second-place finish in the Kaggle competition. 😄🎉

The Flaubert model’s success can be attributed to several factors: - Generalization: Unlike Camembert, Flaubert was less sensitive to noise and specific training data patterns, which translated into better generalization on unseen data. - Computational Efficiency: Flaubert required less computational resources, which allowed us to refine and iterate the model more rapidly. - Adaptability: The model adapted well to the scoring metrics and conditions of the competition.
In conclusion, choosing the Flaubert model over the Camembert approach marks a strategic pivot towards practical deployment scenarios.
4. Mon Ami Français
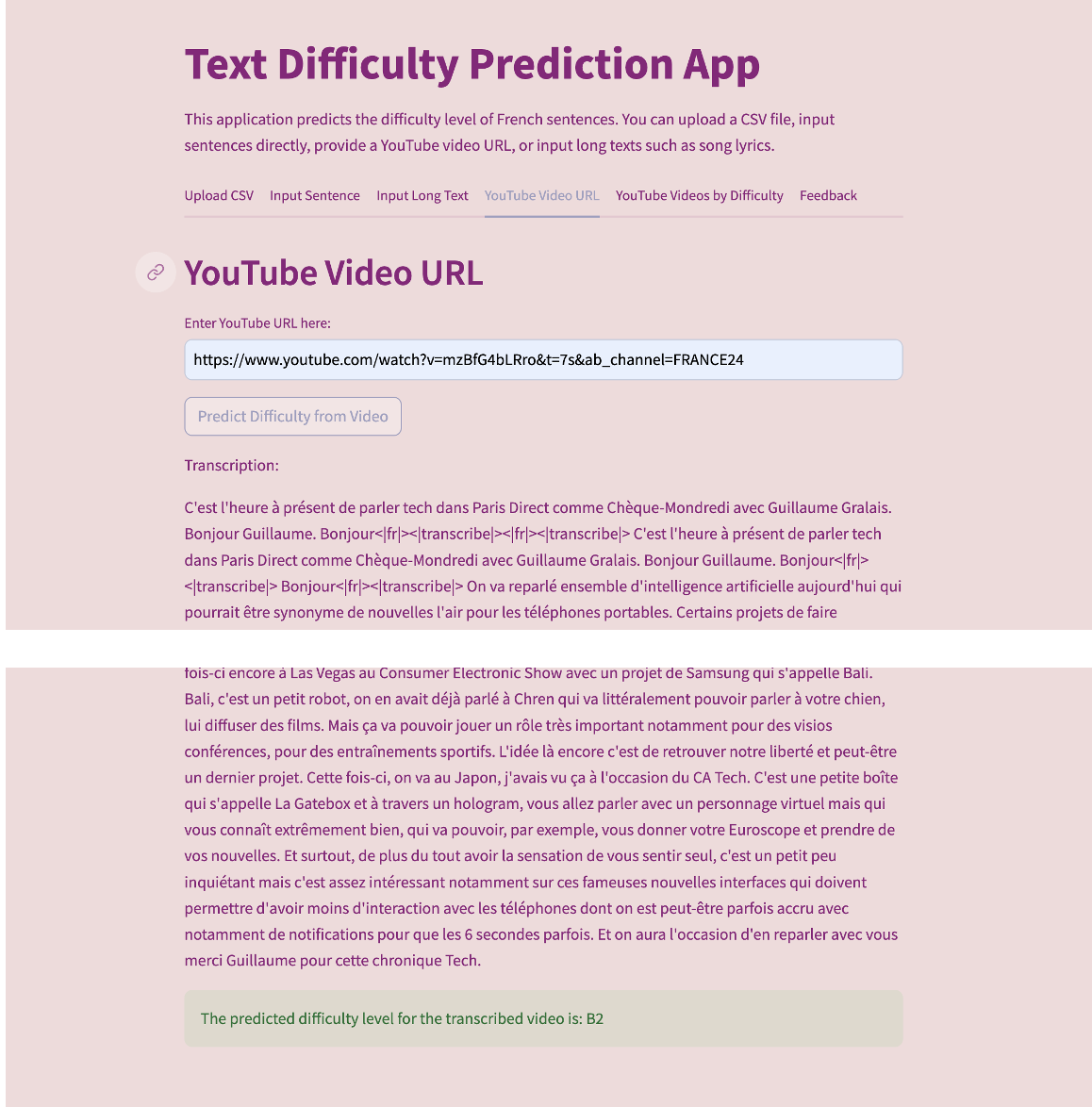
Mon Ami Français is a Streamlit web application that predicts the difficulty level of French sentences. The application leverages the Flaubert model from Hugging Face to analyze and categorize text into different levels of difficulty (A1, A2, B1, B2, C1, C2). Users can upload a CSV file, input sentences directly, or input long texts such as song lyrics. Additionally, the app allows users to find YouTube videos by difficulty level and provide feedback on sentence difficulty.
Features
- Upload CSV: Upload a CSV file containing French sentences, and the app will predict the difficulty level for each sentence.
- Input Sentence: Input a single French sentence to get its difficulty level.
- Input Long Text: Input a longer French text (e.g., song lyrics, paragraphs) to analyze each sentence’s difficulty.
- Find YouTube Videos by Difficulty: Search for French lessons on YouTube categorized by difficulty level.
- Feedback: Provide feedback by inputting a sentence and selecting its difficulty level.
Usage
- Upload CSV: Users upload a CSV file. The sentences are tokenized and processed. The app reads the file, processes the sentences, predicts their difficulty levels, and displays the results in a table. Additionally, a word cloud and a distribution plot of the difficulty levels are generated.
- Find YouTube Videos by Difficulty: Users select a difficulty level from a dropdown menu and click the search button. The app queries YouTube for videos related to French lessons at the selected difficulty level and displays the results with video titles, descriptions, and links to watch the videos.
5. Conclusion
Our project used machine learning to analyze the difficulty, topics, and core vocabulary of French texts from a personalized language learning perspective. We finally built an application to predict the French difficulty of the text, YouTube videos and recommend videos based on their difficulty levels We achieved our initial goals for the project.
Throughout the project, we actively learned and practiced various methods for tokenization, feature extraction, and classification by using different models. In the competition, we optimized our code daily. Initially, we only managed to increase our accuracy by 0.02 each day, and both of our models plateaued at around 0.56. However, when Mariam suggested using an augmented dataset to obtain a new training dataset, our model’s accuracy improved to over 0.60. Based on this improved model, Shiqi developed a simple UI that allows users to input CSV files and sentences to predict their difficulty.
Last but not least, it was a highly enjoyable and collaborative journey. We discussed and organized every part of the project together. When either of us felt nervous about the model’s low accuracy or when the code didn’t run, we encouraged each other. We tried to perfect our project as much as possible, and although we didn’t implement all our ideas due to time constraints, we were thrilled to finish second in the competition. Moreover, we truly enjoyed working together.😘❤️